
Evaluating accuracy of text extraction in OCR systems can be tricky however there are certain metrics available that can be used to evaluate this. These metrics are:
- CER or Character Error Rate
- WER or Word Error Rate
- LER or Line Error Rate
Below we’ll discuss CER and WER Only.
Character Error Rate (CER):
CER measures the rate of erroneous characters produced by an OCR system compared to the ground truth.
CER calculation is based on the concept of Levenshtein distance, where we count the minimum number of character-level operations required to transform the ground truth text into the OCR output.
It is calculated by dividing the total number of incorrect characters by the total number of characters in the reference text. CER is expressed as a percentage.
CER =
Number of incorrect characters
Total number of characters in the reference text
× 100%

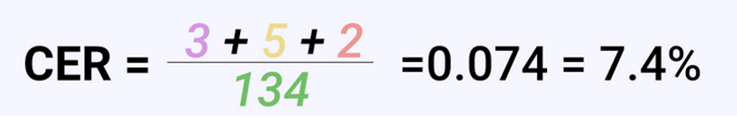
Examples
Reference: “The quick brown fox jumps over the lazy dog.”
Hypothesis: “The qucik brown fox jumpts ove the lazy do.”
So we have 4 errors in the above hypothesis. So CER is calculated as follows
CER = (4 errors / 44 total characters) * 100 = 9.09%
Another Example
- Ground truth text: 619375128
- OCR output text: 61g375Z8
Transformations required to transform OCR output into the ground truth are,
- g instead of 9
- Missing 1
- Z instead of 2
Number of transforms (T) = 1+1+1 = 3
Number of correct characters (C) = 6
CER = T/(T+C) * 100%
= 3/9 *100% = 33.33%
Word Error Rate(WER)
WER evaluates the accuracy of an OCR system at the word level by measuring the proportion of incorrectly recognized words relative to the reference text and is also based on the concept of Levenshtein distance, where we count the minimum number of word-level operations required to transform the ground truth text into the OCR output.
It is computed by dividing the total number of word errors by the total number of words in the reference text.
Formula to calculate WER


Examples
Reference: “The quick brown fox jumps over the lazy dog.”
Hypothesis: “The quick brown fox jump over the lazy dog.”
So 1 word(Jumps) has an error in the Hypothesis out of 9 words.
WER = (1 error / 9 total words) * 100 = 11.11%
Libraries to calcualte CER/WER
- Huggingface Evaluate Library
import evaluate
wer = evaluate.load("wer")
reference = "The cat is sleeping on the mat."
hypothesis = "The cat is playing on mat."
print(wer.compute(references=[reference], predictions=[hypothesis]))- fastwer: https://github.com/kahne/fastwer
- jiwer: https://pypi.org/project/jiwer/
- pywer: https://pypi.org/project/pywer/
- cer: https://pypi.org/project/cer/
- dinglehopper: https://github.com/qurator-spk/dinglehopper
Colab Notebooks
Reference Code to calculate CER/WER
def calculate_wer(reference, hypothesis):
ref_words = reference.split()
hyp_words = hypothesis.split()
# Counting the number of substitutions, deletions, and insertions
substitutions = sum(1 for ref, hyp in zip(ref_words, hyp_words) if ref != hyp)
deletions = len(ref_words) - len(hyp_words)
insertions = len(hyp_words) - len(ref_words)
# Total number of words in the reference text
total_words = len(ref_words)
# Calculating the Word Error Rate (WER)
wer = (substitutions + deletions + insertions) / total_words
return wer
reference_text = "The cat is sleeping on the mat."
hypothesis_text = "The cat is playing on mat."
wer_score = calculate_wer(reference_text, hypothesis_text)
print("Word Error Rate (WER):", wer_score)This code will probably break if the reference and extracted lengths are different.