The openai/MMMLU dataset, also known as the Multilingual Multiple-Choice Test (MMMLU) dataset, is a collection of multiple-choice questions and answers designed to evaluate the performance of AI models across various languages and domains. Here’s a basic summary and some use cases:
Summary of the openai/MMMLU Dataset for Arabic
Overview
- Source: The dataset is provided by OpenAI.
- Content: It contains multiple-choice questions and answers in different languages.
- Structure: Each question is associated with a set of possible answers, and there is a correct answer for each question.
- Languages: The dataset includes questions in multiple languages, such as English, Arabic, Chinese, French, German, Hindi, Japanese, Korean, Portuguese, Russian, Spanish, and more.
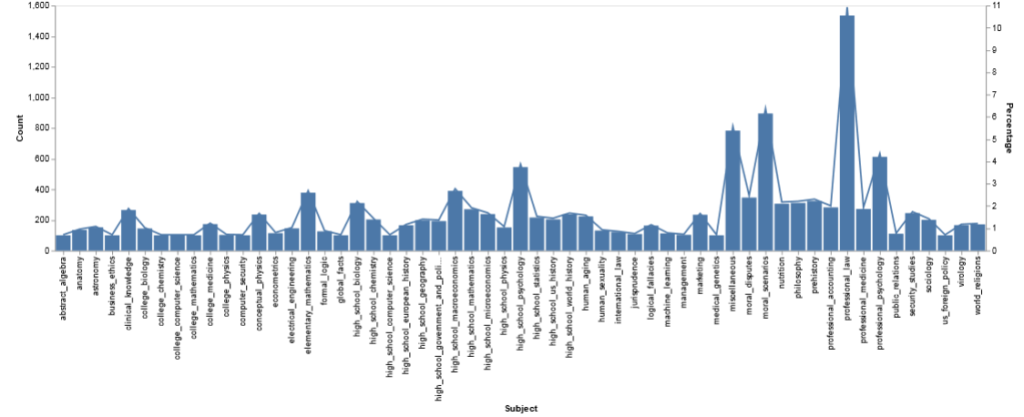
- Domains: The questions cover a wide range of domains, including science, math, social studies, and more.
Data Structure
- Fields: Each entry in the dataset typically includes the following fields:
question: The text of the question.choices: A list of possible answers. (Given as A,B,C,D)answer: The correct answer.subject: The subject or domain of the question.
Use Cases
1. Model Evaluation
- Performance Testing: Use the dataset to evaluate the performance of AI models in multiple languages and domains. This can help identify areas where the model excels or needs improvement.
- Cross-lingual Evaluation: Assess how well a model trained in one language performs in other languages.
2. Educational Applications
- Language Learning: The dataset can be used to create language learning tools and quizzes. For example, you can create a quiz application that presents questions in different languages to help learners practice and improve their language skills.
- Subject-Specific Quizzes: Create quizzes for different subjects to help students test their knowledge and prepare for exams.
3. Research
- Multilingual NLP: Conduct research on multilingual natural language processing (NLP) tasks, such as question answering, text classification, and machine translation.
- Cross-lingual Transfer Learning: Investigate how knowledge learned in one language can be transferred to another language.
4. Data Augmentation
- Dataset Expansion: Use the dataset to augment existing datasets for training and testing AI models. This can help improve the robustness and generalization of the models.
5. Content Generation
- Question Generation: Use the dataset as a reference to generate new multiple-choice questions for various applications, such as educational tools, quizzes, and assessments.
- Answer Verification: Develop systems to verify the correctness of answers to multiple-choice questions.
Example Use Case: Creating a Language Learning Quiz
- Filter the Dataset: Extract questions in the desired language (e.g., Arabic) and subject (e.g., Science).
- Create a Quiz Application: Develop a web application that presents these questions to users and allows them to select answers.
- Evaluate User Performance: Track the user’s performance and provide feedback to help them improve.
Available Splits in the Dataset
{
“splits”: [{
“dataset”: “openai/MMMLU”,
“config”: “default”,
“split”: “test”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “AR_XY”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “BN_BD”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “DE_DE”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “ES_LA”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “FR_FR”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “HI_IN”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “ID_ID”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “IT_IT”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “JA_JP”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “KO_KR”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “PT_BR”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “SW_KE”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “YO_NG”
}, {
“dataset”: “openai/MMMLU”,
“config”: “by_language”,
“split”: “ZH_CN”
}],
“pending”: [],
“failed”: []
}
Code on Google Colab
Question Count by different subjects